二次开发
本节将介绍如何进行二次开发,建议先了解前面的内容再看本节
# 概述
在二次开发前,咱们先来再次回顾一下咱们这套系统的架构
如下图所示
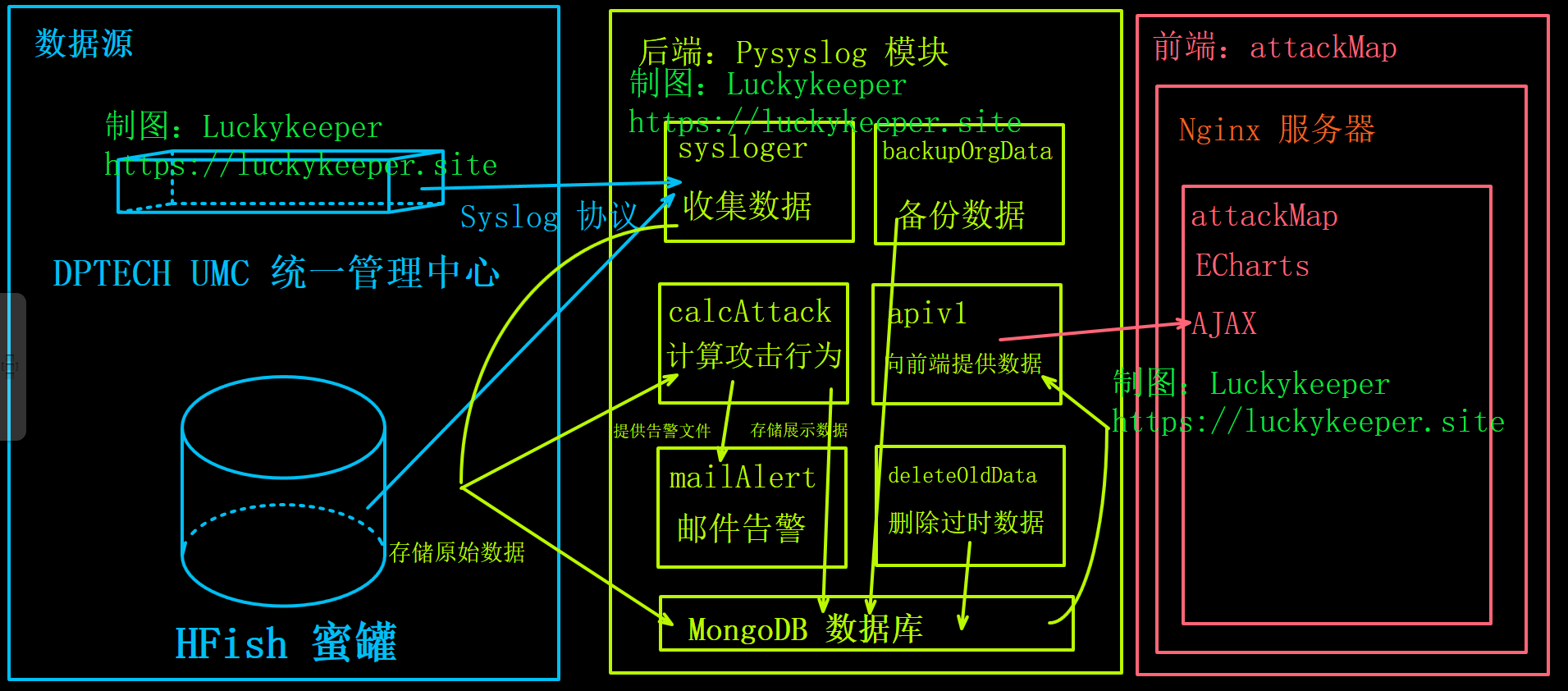
# sysloger 模块
sysloger 模块是二次开发的重点,你只需要按照格式处理好数据送到 orgData/syslog 数据库内,就可以把你的数据源轻松纳入本套系统,后面 calcAttack 模块就会对数据进行统一整理,并交由 apiv1 模块向前段传数据
# 数据要求
如下表,写入 MongoDB 的 orgData/syslog 中
以下均为 key_value 格式
| 名称 | 说明 | 示例 |
|---|---|---|
| srcIp | 发起攻击的IP地址 | 177.20.249.60 |
| attackTime | 发起攻击的时间 | 2022-03-20 18:11:54 |
| destName | 攻击目标,对于蜜罐类数据源可以固定名称“蜜罐1号”,对于 WAF 类数据源可以展示 IP 地址,不做强制要求,不参与后续计算 | 见左 |
| destLocX | 被攻击服务器的经度,请手动指定,不参与后续计算 | 115.506601 |
| destLocY | 被攻击服务器的纬度,请手动指定,不参与后续计算 | 38.926478 |
| dataSource | 数据来源,请根据数据实际来源填写,不参与后续计算 | DPTECH |
| atkType | 攻击类型, WAF 类会传这样的数据过来,蜜罐类一般填写“ scan ”或者" attack " | Icmp unreach |
| action | 我方的相应动作, WAF 类会传这样的数据过来,蜜罐类一般填写"记录" | alert |
最终写入数据库数据示例如下
{'srcIp': '106.118.146.113', 'attackTime': '2022-03-20 18:14:56', 'destName': '123.123.123.123', 'destLocX': '115.506601', 'destLocY': '38.926478', 'dataSource': 'DPTECH', 'atkType': 'Icmp unreach', 'action': 'alert'}
# 基于 syslog 的二次开发
如果你的数据源支持 syslog ,那二次开发就会非常容易,所以建议优先考虑 syslog
# Step01:确定数据来源
有多个数据来源的时候,区分不同的数据来源很有必要,可以方便后面的处理,就像垃圾分类一样,我们的第一步当然是要给进来的数据打上 Tag ,我们利用 re 库来识别,你需要写类似下面的代码
# 来自蜜罐的数据
honeypotRe = re.compile('HFish')
# 来自 WAF 的数据
wafRe = re.compile('DPTECH')
# 判断蜜罐数据
if honeypotRe.search(orgData) != None:
if debug == True:
print("数据来自蜜罐!")
# 打上蜜罐 Tag
dataTag = "honeypotTag"
# 来自 WAF 的数据
elif wafRe.search(orgData) != None:
if debug == True:
print("数据来自 WAF !")
# 打上 WAF Tag
dataTag = "wafTag"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
二次开发时,你需要寻找数据源传来的独特数据,一般是系统名称,比如 'HFish' 这样的,然后给对应的数据打上 Tag ,不同的 Tag 对应后面不同的数据处理动作
# Step02:处理数据
按照上面的数据要求处理数据成为指定格式即可,通常使用 .split 方法对文本进行分割,这部分的写法详见源码
# Step03:写入数据库
如下,非常简单
# 整理将要写入数据库的数据
result_db = {}
result_db['srcIp'] = srcIp
result_db['attackTime'] = attackTime
result_db['destName'] = destName
result_db['destLocX'] = destLocX
result_db['destLocY'] = destLocY
result_db['dataSource'] = dataSource
result_db['atkType'] = atkType
result_db['action'] = action
## Debug 输出将要写入数据库的数据
if debug == True:
print("将要写入数据库的数据",result_db)
# 数据统一写入 MongoDB 的 orgData/syslog 数据库
try:
client = MongoClient(MongoDB_host, MongoDB_port)
db = client.admin # 先连接系统默认数据库admin进行认证
db.authenticate(MongoDB_user, MongoDB_password,mechanism='SCRAM-SHA-1')
if debug == True:
print(">>>>>>MongoDB数据库连接成功!")
newDb = client[MongoDB_dbName]
newCol = newDb[MongoDB_col]
newCol.insert_one(result_db)
if debug == True:
print("数据成功写入!")
except:
print("请检查数据库设定是否正确!")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 基于其它数据库的二次开发
方法和上面一样,我原先在 HFish 不支持 syslog 的时候,写过从它的 sqlite 数据库提数据的程序,非常简单
# calcAttack 模块
这个模块负责信息的统一计算,你可能会想要修改其中的一些参数
因为这套系统是给学校开发的,学校比较大, 192.168.0.0/16 段全部都用上了,所以程序会让 192.168.0.0/16 段全部返回的位置是“局域网”,你可能会需要修改这里,这里模块是用正则表达式判断的,你需要先学习怎么写正则表达式
模块中判断 192.168.0.0/16 段的代码如下
pattern = re.compile('(?:(?:10(?:(?:\.1[0-9][0-9])|(?:\.2[0-4][0-9])|(?:\.25[0-5])|(?:\.[1-9][0-9])|(?:\.[0-9])))|(?:172(?:\.(?:1[6-9])|(?:2[0-9])|(?:3[0-1])))|(?:192\.168))(?:(?:\.1[0-9][0-9])|(?:\.2[0-4][0-9])|(?:\.25[0-5])|(?:\.[1-9][0-9])|(?:\.[0-9])){2}')
# 其它模块
一般来说,其它模块应该没有什么开发需求,相互依赖性也不强,开发其它模块请直接起个新的文件来写